Problem
There is a delicate balance on performance when it comes to setting up the indexes on a table. Too many indexes and your INSERT / UPDATE / DELETE performance will suffer, but not enough indexing will impact your SELECT performance. This tip will look at the order of the columns in your index and how this order impacts query plans and performance.
Solution
Sample SQL Server Table and Data Population
For this example we will setup two sample tables and populate each of the tables with data. Here is the code:
Before we run the following commands include the actual execution plan (Ctrl + M) and also turn on Statistics IO by running "SET STATISTICS IO ON" in the query window.
Single Table Query Example
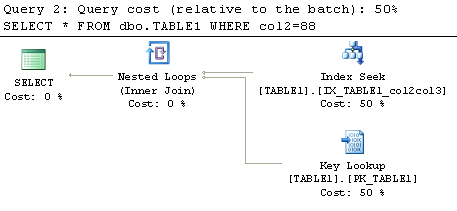
For our first example let's take a look at a simple query with one column in the WHERE clause. The first query uses the second column (col3) of the index in the WHERE clause and the second query uses the first column (col2) of the index in the WHERE clause. Note we are using "DBCC DROPCLEANBUFFERS" to ensure the cache is empty before each query is executed. Here is the code:
Before running the command turn on the execution plan. Looking at the explain plans for these two queries we can see that the query that uses the second column (col3) of the index in the WHERE clause is performing an index scan on PK_TABLE1 and not even using the index we created on the column. The second query which has the first column (col2) of the index in the WHERE clause is performing a seek on the index we created and even on this small table uses fewer resources, 6 reads as compared to 4 reads, to execute this query. You can probably guess that this increase in performance only increases as the table becomes larger.

Two Table Join Query Example
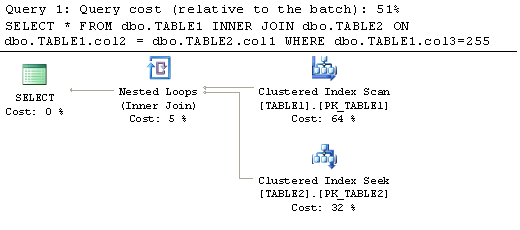
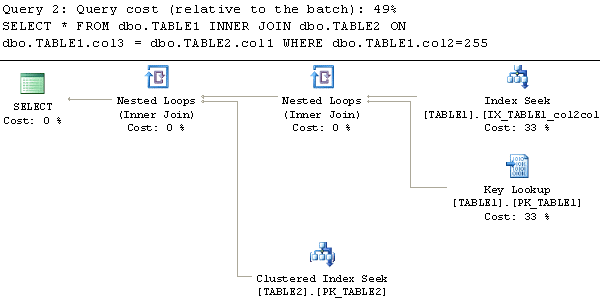
For our next example let's take a look a query that has the same WHERE clause but also adds an inner join to another table. We will again have two queries. The first query has the second column (col3) of the index in the WHERE clause and the first column (col2) of the index is used to join the table. The second query has the first column (col2) of the index in the WHERE clause and second column (col3) of the index is used to join the table. Again we are using "DBCC DROPCLEANBUFFERS" to ensure the cache is empty before each query is executed. Here is the code:
Looking at the explain plans for these two queries we can see that when the column that the tables are joined on appears first in the index the query does an index scan of this table (as it did in the first example). The second query which has the first column of the index in the WHERE clause is performing a seek on the index we created. Again this second query uses fewer resources to complete, 6 reads as compared to the 8 reads required by the first query doing the scan. This increase in performance will also become greater as more data is added to these tables, as was the case in the previous example.
Summary
You can see from these simple examples above that the ordering of the columns in your index does have an impact on how any queries against the tables will behave. A best practice that I've followed that has been quite helpful when creating indexes is to make sure you are always working with the smallest result set possible. This means that your indexes should start with any columns in your WHERE clause followed by the columns in your JOIN condition. A couple more steps that also help query performance is to include any columns in an ORDER BY clause as well as making the index a covering index by including the columns in your SELECT list, this will remove the lookup step to retrieve data. One thing I mentioned earlier that I want to re-interate here is that by adding more indexes to tables as well as adding more columns to an existing index it will require more resources to update these indexes when inserting, updating and deleting data, so finding a balance is important.
No comments:
Post a Comment